GitHub
O GitHub é considerado uma ferramenta essencial para engenheiros de software, com uma popularidade sem igual. Em geral, o GitHub é um serviço baseado em nuvem que hospeda um sistema de controle de versão (VCS) chamado Git, sendo esse a tecnologia que o sustenta. Ele permite que os desenvolvedores colaborem e façam mudanças em projetos compartilhados enquanto mantêm um registro detalhado do seu progresso. Ele é um sistema de controle de versão, isso significa que mesmo após um projeto ser lançado é comum a atualização de versões, correção de bugs, adição de novas ferramentas, etc. Esse sistema ajuda acompanhar as mudanças feitas no código base. E mais, ele também registra quem efetuou a mudança e permite a restauração do código removido ou modificado.
Git é um sistema de controle de versão desenvolvido por Linus Torvalds (o criador do Linux). Ele é considerado o coração do GitHub, possibilitando qualquer desenvolvedor em uma equipe de gerenciar o código fonte e seu histórico de mudanças usando ferramentas de linha de comandos de Git, desde que ele tenha acesso para isso.

Repositórios
Os repositórios são ambientes criados para armazenar seus códigos. Você pode possuir um ou mais repositórios, públicos ou privados, locais ou remotos. É através dos seus repositórios públicos que outros programadores poderão ter acesso ao seu código no GitHub, podendo, inclusive, cloná-los para adicionar melhorias.
Branch
Branco é o nome dado a uma versão (ramificação do projeto). Isso é útil porque possibilita gerenciar múltiplas alterações acontecendo simultaneamente.
Merge
Para unir as modificações feitas em um branch ao código original, utilizamos o comando merge. Com esta funcionalidade, todas as alterações feitas em cópias manipuláveis são inseridas, após aprovadas, no código-fonte original sem complicações.
Fork
Quando um profissional desenvolvedor precisa começar a trabalhar em um projeto, seu primeiro passo é copiar este repositório para a sua máquina. Este processo é realizado pelo comando fork.
Principais Comandos Git:
• Init: este comando dá origem a um repositório novo, local ou remoto, ou reinicializa um repositório já existente;
• Clone: este comando clona o código de um repositório para sua manipulação em outro ambiente;
• Commit: este comando move os arquivos da state area para um repositório local;
• Add: este comando adiciona um arquivo alterado a uma staging area, ou seja, o prepara para ser vinculado a um commit;
• Push: este comando envia arquivos de um repositório local para um repositório remoto. No GitHub, por exemplo;
• Pull: ao contrário do push, este comando traz um arquivo do repositório remoto para o repositório local.
• Log: este comando permite a visualização do histórico de commits de um arquivo ou usuário, ou o acesso de uma versão específica.
Por que o GitHub é tão popular?
O GitHub é um projeto de gestão baseado em nuvem e uma plataforma de organização que incorpora os recursos de controle de versão do Git. Isso significa que todos os usuários do GitHub podem acompanhar e gerenciar as mudanças feitas para o código-fonte em tempo real, enquanto têm acesso a todos os outros recursos do Git disponíveis no mesmo lugar. O GitHub também serve como um site de rede social onde os desenvolvedores podem se relacionar abertamente, colaborar e divulgar seu trabalho. Além disso, a interface de usuário do GitHub é mais amigável do que a do Git, fazendo com que seja mais acessível para pessoas que possuem pouco ou nenhum conhecimento.
Gitflow
O Gitflow é um fluxo de trabalho legado do git que no começo era uma estratégia inovadora e revolucionária para gerenciar ramificações do git. Porém ele perdeu popularidade para fluxos de trabalho baseado em troncos, que hoje são recomendados para o desenvolvimento moderno e contínuo de softwares e práticas de DevOps. Entretanto, para fins acadêmicos, este artigo irá descrever o que é o Gitflow e como ele funciona.
O Gitflow é um modelo, uma estratégia ou, ainda, um fluxo de trabalho muito utilizado por equipes de desenvolvimento de software. Ele se destaca por auxiliar na organização do versionamento de códigos. Ele foi introduzido pelo desenvolvedor de software Vincent Driessen em 2010. Fundamentalmente, o fluxo do Git envolve isolar seu trabalho em diferentes tipos de ramificações. O Gitflow é recomendado para projetos que utilizam versionamento semântico (semantic versioning) ou que precisam oferecer suporte A várias versões do software. A utilização do Git Flow também se torna recomendado para projetos que existam uma grande quantidade de pessoas “commitando” dentro de um repositório, ou para projetos que possuem um ciclo de entrega agendada.
Como funciona?
O Git Flow estabelece algumas regras de nomenclaturas para tipos de branchs enquanto, ao mesmo tempo, define o que cada tipo de branch faz. O modelo é composto por branchs de vida infinita (develop e master) que mantém o código em desenvolvimento e produção basicamente, e branchs de suportes (Feature, Release e Hotfix) que auxiliam no processo de desenvolvimento do sistema. Estas últimas possuem regras que estabelecem onde são iniciadas e onde são mescladas. Na imagem abaixo, vemos como é a estrutura do fluxo do Git Flow.
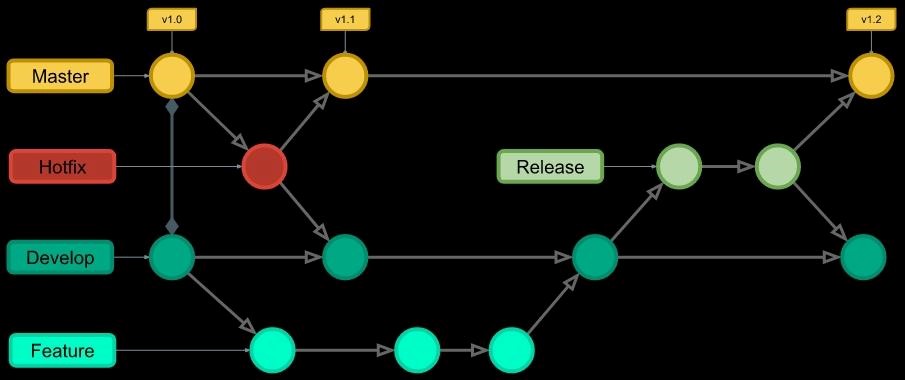
Tipos de branchs
Branch Master/Main: Branch que contém código em nível de produção, ou seja, o código mais maduro existente na sua aplicação. Todo o código novo produzido eventualmente é juntado com a branch master em algum momento do desenvolvimento. Possui ciclo de vida eterno.
Branch Develop: É a branch onde fica o código do próximo deploy. Ela serve como uma linha do tempo com os últimos desenvolvimentos, isso significa que ela possui funcionalidades que ainda não foram publicadas e que posteriormente vão ser associadas com a branch Master.
Branch Feature: A ramificação de recurso é o tipo mais comum de ramificação no fluxo de trabalho do fluxo do Git. Ele é usado ao adicionar novos recursos ao seu código. Ao trabalhar em um novo recurso, você iniciará uma ramificação de recurso fora da ramificação de desenvolvimento e, em seguida, mesclará suas alterações de volta na ramificação de desenvolvimento quando o recurso for concluído e devidamente revisado.
Branch Hotfix: No fluxo do Git, a ramificação de hotfix é usada para abordar rapidamente as alterações necessárias em sua ramificação principal. A base da ramificação hotfix deve ser sua ramificação principal e deve ser mesclada de volta nas ramificações principal e de desenvolvimento. Mesclar as alterações de sua ramificação de hotfix de volta à ramificação de desenvolvimento é fundamental para garantir que a correção persista na próxima vez que a ramificação principal for lançada.
Branch Release: A ramificação de lançamento deve ser usada ao preparar novos lançamentos de produção. Normalmente, o trabalho que está sendo executado em branches de lançamento diz respeito a retoques finais e pequenos bugs específicos para liberar um novo código, com código que deve ser tratado separadamente do branch principal de desenvolvimento.
Docker
Docker é um conjunto de produtos de plataforma como serviço que usam virtualização de nível de sistema operacional para entregar software em pacotes chamados contêineres os contêineres são isolados uns dos outros e agrupam seus próprios softwares bibliotecas e arquivos de configuração eles podem se comunicar uns com os outros por meio de canais bem definidos todos os contêineres são executados por um único Kernel do sistema operacional e portanto usam menos recursos do que as máquinas virtuais .
O docker é uma alternativa de virtualização em que o kernell da máquina hospedeira é compartilhado com a máquina virtualizada ou o software em operação portanto um desenvolvedor pode agregar a seu software a possibilidade de levar as bibliotecas e outras dependências do seu programa Junto ao software com menos perda de desempenho do que a virtualização do hardware de um servidor completo assim o docker torna operações em uma infraestrutura como serviços web mais intercambiável eficiente e Flexível .
Docker vs Máquina Virtual
Embora o Docker e as máquinas virtuais tenham um propósito semelhante, seu desempenho, portabilidade e suporte a sistemas operacionais diferem significativamente. A principal diferença é que os containers do Docker compartilham o sistema operacional do host, enquanto as máquinas virtuais também têm um sistema operacional convidado sendo executado no sistema host. Esse método de operação afeta o desempenho, as necessidades de hardware e o suporte do SO.
Como o Docker Funciona?
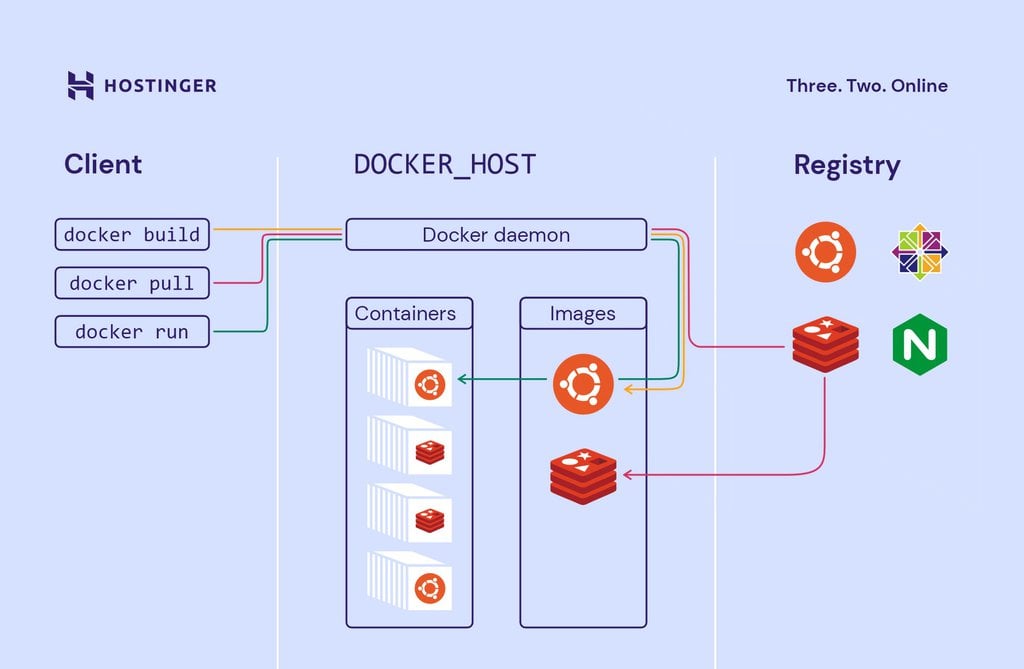
A arquitetura do Docker consiste em quatro componentes principais junto com os containers do Docker que abordamos anteriormente.
• Cliente Docker– o principal componente para criar, gerenciar e executar aplicativos em container. O cliente Docker é o principal método de controle do servidor Docker por meio de uma ILC, como Prompt de Comando (Windows) ou Terminal (macOS, Linux).
• Servidor Docker– também conhecido como o daemon do Docker. Ele aguarda as solicitações da API REST feitas pelo cliente Docker e gerencia imagens e containers.
• Imagens do Docker– instrua o servidor Docker com os requisitos sobre como criar um container Docker. As imagens podem ser baixadas de sites como Docker Hub. A criação de uma imagem personalizada também é possível — para isso, os usuários precisam criar um Dockerfile e passá-lo para o servidor. Vale a pena notar que o Docker não limpa nenhuma imagem não utilizada, então os usuários precisam excluir dados de imagem eles mesmos, antes que acabe com muitas delas.
• Registro do Docker– um aplicativo do lado do servidor de código aberto usado para hospedar e distribuir imagens do Docker. O registro é extremamente útil para armazenar imagens localmente e manter controle total sobre elas. Como alternativa, os usuários podem acessar o Docker Hub mencionado acima – o maior repositório mundial de imagens do Docker.
CI/CD
CI/CD (Continuous Integration/Continuous Delivery), pode ser referir às práticas combinadas de integração contínua e entrega contínua. CI/CD Preenche as lacunas entre as atividades e equipes de desenvolvimento e operação reforçando a automação na compilação teste e implantação de aplicativos o processo contrasta com os métodos tradicionais onde todas as atualizações eram integradas em um grande lote antes de lançar a versão mais recente as práticas modernas de DevOps envolvem desenvolvimento contínuo teste contínuo integração contínua implantação contínua e monitoramento contínuo de aplicativos de software ao longo de seu ciclo de vida de desenvolvimento a prática de CI/CD ou pipeline de CI/CD forma a espinha dorsal das operações DevOps modernas.
CI/CD
CI se refere à integração contínua (processo de automação para desenvolvedores). Ela é ideal para evitar conflitos entre ramificações no repositório de controle de versão quando há desenvolvimento simultâneo de várias aplicações. Para que seja bem-sucedida, requer desenvolvimento, testes e consolidação frequentes de mudanças no código de uma aplicação. Esta é uma etapa importante já que se inicia o ciclo (no desenvolvimento) do pipeline, e assim, é possível formalizar a diminuição do tamanho do lote a cada contribuição frequente de código.
Já CD representa entrega contínua e/ou implantação contínua. Ambos tratam da automação de fases avançadas do pipeline, mas podem ser usados de forma separada para ilustrar o nível de automação presente.
De forma geral, é importante saber que o CI/CD é, na verdade, um processo muitas vezes visto como um pipeline. Isso porque ele envolve a inclusão de um alto nível de automação e monitoramento contínuos no desenvolvimento de aplicações. Pode acontecer, por exemplo, de uma empresa começar adicionando CI e, depois, trabalhar para automatizar a entrega e implantação.
Quer um exemplo de aplicação prática da CI/CD?

No processo de desenvolvimento moderno de aplicações, é comum que muitos desenvolvedores trabalhem ao mesmo tempo em diferentes recursos na mesma aplicação. No momento de consolidar todo o código-fonte de ramificação em apenas um dia (merge day), o trabalho poderá ser entediante, manual e bem demorado, com conflitos em aplicações de cada desenvolvedor.
Com a integração contínua (CI), os desenvolvedores consolidam as mudanças no código de volta a uma ramificação compartilhada ou “tronco” com maior frequência. Depois, as mudanças são consolidadas e validadas por meio da criação automática da aplicação. Tudo é testado, incluindo classes, funções e diferentes módulos que formam toda a aplicação. Se houver conflito entre os códigos novos e existentes, a CI facilita a correção desses bugs com rapidez e frequência. A etapa final de um pipeline de CI/CD é a implantação contínua. Ela automatiza o lançamento de uma aplicação para a produção e depende muito da automação otimizada dos testes.
Computação em Nuvem
A computação em nuvem é uma forma de fornecer recursos de computação (como servidores, armazenamento e software) pela Internet. Em vez de comprar e gerenciar hardware e software em seus próprios data centers, as empresas podem usar serviços de nuvem para expandir ou reduzir rapidamente sua capacidade de computação, pagar apenas pelo que usam e escalar de acordo com as necessidades de seus negócios. A computação em nuvem oferece muitos benefícios, incluindo maior flexibilidade, eficiência, escalabilidade e redução de custos.
Computação em Nuvem

Quais são os serviços de computação em nuvem?
Há muitos benefícios relacionados ao uso deste tipo de recurso, o econômico acaba se sobressaindo, porém, vale lembrar quais são alguns dos produtos da computação em nuvem. Os serviços são divididos em quatro opções: IaaS, PaaS, SaaS e Sem Servidor. Vamos conhecer:
• IaaS (Infraestrutura como serviço): Neste caso, a empresa fornece o acesso sob demanda a recursos fundamentais da computação como armazenamento, servidores físicos virtuais, rede, sistemas operacionais, etc;
• PaaS (Plataforma como serviço): Com o uso dessa opção, o que é fornecido é um ambiente para desenvolvimento, testes, fornecimento e gerenciamento de aplicativos. Ele é feito para desenvolvedores de vários tipos distintos;
• SaaS (Software como serviço): Ao usar esse serviço do cloud computing, a empresa passa a ter em mãos um ambiente no qual consegue oferecer a seus clientes um software em nuvem sob demanda. Aqui, os provedores hospedam e gerenciam o aplicativo que os usuários pagarão para acessar via web;
• Computação sem servidor: Também conhecido como serverless computing, esse tipo de serviço faz com que o provedor seja o responsável por cuidar da configuração, planejamento e gerenciamento dos servidores. Tudo feito apenas em momentos solicitados pelo cliente.
Modelos de computação em nuvem
• Nuvem pública: Este tipo coloca o provedor dos serviços de nuvem como o centro da plataforma. Ele oferece recursos de computação para clientes através de uma internet pública. O Google Cloud é um exemplo de nuvem pública;
• Nuvem privada: Funcionando como um serviço estruturado e que funciona exclusivamente para um único cliente, a nuvem privada tem os seus recursos direcionados a uma empresa ou organização. Há quem diga que a segurança é um dos principais fatores que faz uma companhia optar por esse tipo;
• Nuvem híbrida: Essa opção de serviço une ambas, nuvem pública e nuvem privada em uma infraestrutura única e flexível para oferecer uma certa flexibilidade para a empresa ou organização.
O que é possível fazer com a computação em nuvem?
Testar aplicativos, Desenvolver aplicativos, Armazenar dados, Fazer backup de dados, Streaming, Fornecer software sob demanda, Fazer análise de dados, Criar e editar documentos online